In applications where users are interested in getting measurement
values (e.g., Humidity Level) in a specific location, and there
are many humidity sensors devices in the same location, user may
need a ranking mechanism for the results.
The following lists the key design consideration for IoT data
indexing and discovery,
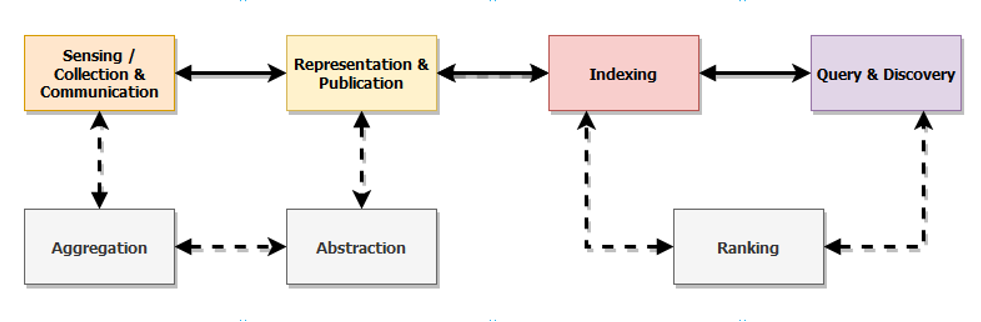
1. Sensing / Collection & Communication
This part included interactions and communications between
different sensory devices on a network and the necessary
mechanisms that allow seamless communication with these embedded
devices. Sensory devices can register to the network or the
network itself has to crawl and detect them automatically.
2. Aggregation
This part included data from multiple, distributed and pervasive
sources is combined and aggregated before being transmitted to a
base station (e.g. A sink node or a gateway) for further
processing. The key challenge in data aggregation is that data
from different sources could have different data models and
various granularities.
3. Abstraction
This part included data from multiple, distributed and pervasive
sources is combined and aggregated before being transmitted to a
base station (e.g. A sink node or a gateway) for further
processing. The key challenge in data aggregation is that data
from different sources could have different data models and
various granularities.
4. Representation
This part included data from multiple, distributed and pervasive
sources is combined and aggregated before being transmitted to a
base station (e.g. A sink node or a gateway) for further
processing. The key challenge in data aggregation is that data
from different sources could have different data models and
various granularities.
5. Publication
IoT data usually require to be accessed and integrated with other
real-world data; it needs to be published in
human-readable/machine-understandable formats. It should also be
published and stored in distributed locations (e.g. repositories
or cloud services. The publication process might involve semantic
annotation or interpretation of multiple sources to express and
represent the data in a formal language and allow interoperability
between the sources. Interoperability between multiple sources
provides high-level sematic reasoning for low-level sensor data.
It is noteworthy that deciding whether IoT data should be
published with/without abstraction and/or aggregation is often
application dependent. For example, it is required to process all
raw data in healthcare application because every single data point
can be significant. Whereas, data should be aggregate in traffic
application to summaries the data (e.g. High traffic, low traffic)
and reduce the computational, storage and communication overhead
within the network.
6. Indexing
Indexing large volumes of heterogeneous and dynamic IoT
data/sources requires distributed, efficient and scalable
mechanisms that can provide a fast access and retrieval to data in
order to respond to user queries. A decision on how often these
indexes should be updated and re-arranged while data streams are
continuously published is crucial to enable on-line indexing. With
on-line indexing, building indexing structures is incremental with
the goal to update the indexes continuously with the new connected
resource and the data that becomes available on the network
without re-building the entire indexing structure.
7. Discovery
Data discovery is about accessing specific sources to get the
requested data and analyse it. On-line data discovery brings
another dimension to play; access and analysis of on-line data
from different sources, while other data is continuously
published, is a challenging task. The accessing process is based
on requested queries to find(search) data sources, patterns or
events. Collaborative services are used on the obtained data from
different sources to make analysis and provide intelligent
decisions. Data can also be stored in repositories for temporary
(short-term) or archived for long-term use. Data discovery could
be limited by a time interval (time between two consecutive data
points) in the processing of data for disaster monitoring.
8. Ranking
Ranking IoT resources requires the prioritisation of several
criteria (e.g. Data quality, devices availability, efficient
energy and network bandwidth and latency), especially if there is
the same type of services (e.g. temperature) at the same location.
The ranking is a multi-objective decision-making process in which
different criteria should be considered depending on the
requirements and the network/device status. For instance,
healthcare applications require trust and high-quality data.
Emergency cases require transmitting and processing data with low
latency to provide on-line command and control mechanisms.
9. Query
End-users (i.e. machines or human users) in IoT applications may
discover and query a certain data type at a particular location
and at a specific time (e.g. current temperature). A query can be
composed of type, location, and time attributes (i.e. type) now.
Other possible types of queries are proximity, range and composite
queries. Accessing location data to find a source of a particular
type (e.g. temperature) needs to be handled by a discovery
mechanism. It is important that deciding which data should be
collected/crawled, how the data is represented and published and
how users can interact with different applications are often
application dependent. Indexing could be for a resource (i.e.
sensory devices) or data (data published by resources. Indexing
the resources allows on-line access to the resource and their
published data at anytime.